
Introducing Hive
If you’re not building your own agent orchestration tool, what are you even doing bro? 🐝🍯🦞

That’s right, I’ve built my own bespoke agent tool. Lobsters are now the hottest animal on the block and all the talk is about agent swarms and orchestration and SOUL.md files. I wasn’t quite ready to setup my own OpenClaw and give it all of the necessary (and risky) credentials, but I wanted to experiment with some of these ideas. So of course I built my own.
The point here is not to convince you to use my tool. You could—alright maybe you should—but what I really want to say is why I built a new thing and what matters in the world of getting stuff done with AI right now.
Let’s start with the name of my tool: it’s called Hive.
Hive starts way back in the 17th century with a quote from Francis Bacon’s book Novum Organum. This is one of the first descriptions of the scientific method and in one passage he uses insects as an analog for how to acquire knowledge:
The men of experiment are like the ant, they only collect and use; the reasoners resemble spiders, who make cobwebs out of their own substance. But the bee takes the middle course: it gathers its material from the flowers of the garden and field, but transforms and digests it by a power of its own.
That’s what I wanted from my agent use. So a reasonable aspiration was to build a hive. 🐝🍯
The first version of this project started with a much heavier focus on orchestration. I was deep into my tokenmaxxing phase—which I also think of as agent adolescence, we all have to go through it—and I was desperately trying to eke every token out of every model I could get my grubby hands on. I wanted to use Claude Opus and Sonnet and Codex and a local Qwen or Gemma and even Haiku and let them sort it all out. And so I built a steward agent that managed task complexity and distributed work out to all of the available models. It had a local web interface and different personalities and all sorts of dumb logic that’s been recreated by model providers in a vastly better way and it broke pretty much every day.
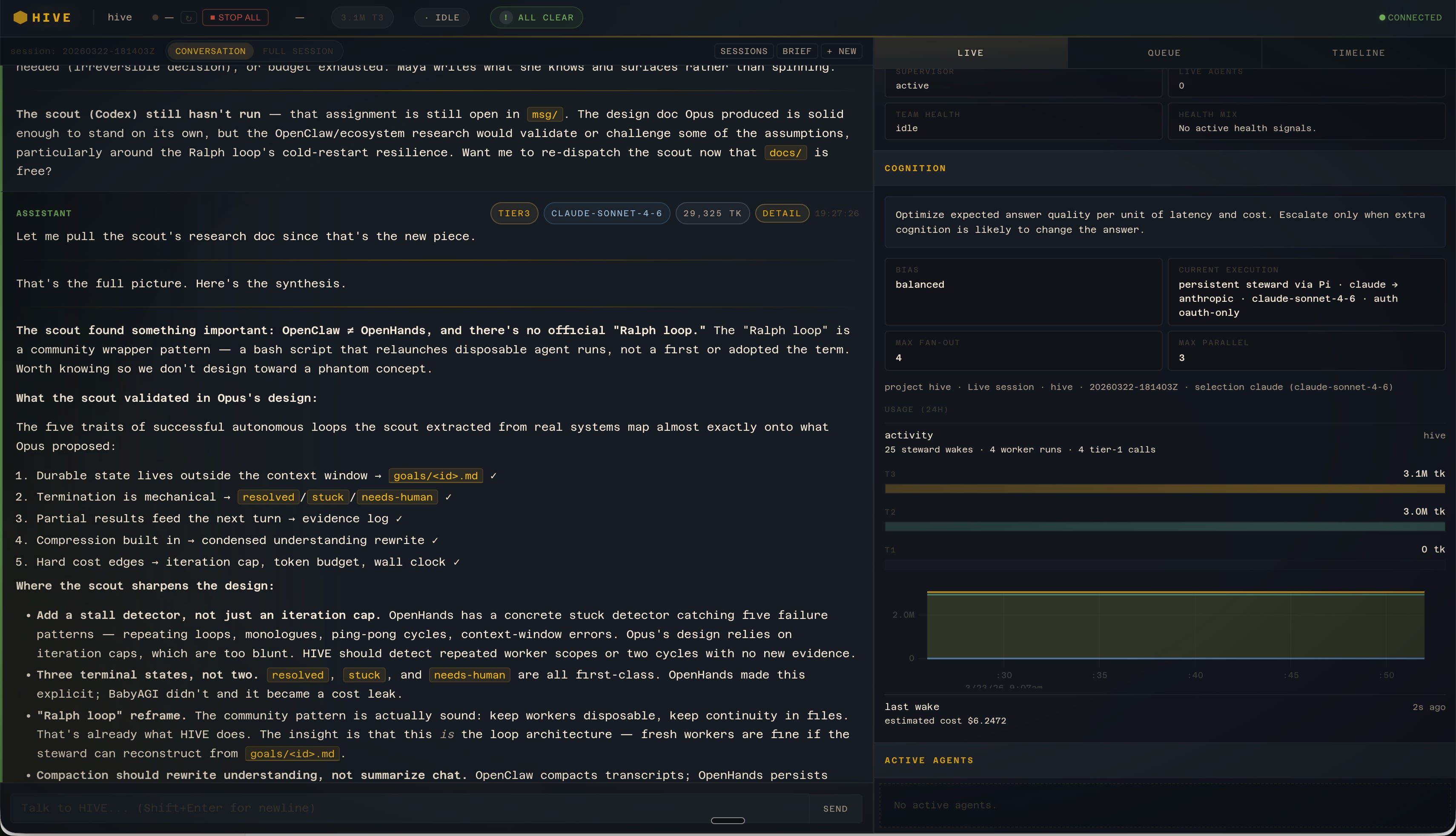
It wasn’t working and I almost just stopped. But I also knew I wasn’t happy with Claude Code all by itself.
The problem with all these orchestration frameworks is that they’re all so early. Developers see what one well-defined agent can do and want to spin up 1,000 more. The agents will magically coordinate with each other on their own, no problem, we think, and we happily forget the lessons of Fred Brooks and that nine pregnant women can’t make a baby in one month and are surprised when our token budget for the week is exhausted in the first 45 minutes even though there’s no work to show for it. So it’s not that I don’t believe in agent swarms. It’s just that right now they’re more like an agent soup.
What I do believe in right now is context. Context is king and you need to grab it and hoard it every chance you get. The reason that Claude Code is so much better than just Claude in the first place is context. That’s what a harness does. Tools are context. Files are context. Memories are context. Once we start really getting context right, we’ll be able to turn that soup back into swarms. Multi-agent orchestration is going to change what work means in our entire civilization..it’s just 3 months or 3 years away. Always right around the corner.

We’re so early.
Early enough that all the labs are moving as fast as they can with the smartest people in the world and some Austrian guy (Peter Steinberger) beat them to a whole series of unlocks basically by himself. And now we have lobsters. OpenClaw is an amazing project because it was someone experimenting and building what he wanted for himself.
Now Anthropic is migrating all “programmatic use” of its models away from subscriptions and to the API. I talked to a couple of friends about it and they didn’t seem as perturbed because the subscriptions are still such a good subsidized deal. But what it signifies to me is vendor lock-in. If the harness is at least as important as the model, then what we’re really buying now with a subscription is access to specific tools, not models.
If context is the most important thing, and harnesses are the best way so far to manage context, then the new job is to understand and control harnesses in the same way we’re used to controlling our shell or our container or our editor.
What this means will evolve over time and implementation will vary based on taste and need. Mario Zechner felt so strongly about it that he made Pi.dev, which then became a part of OpenClaw. (you should definitely watch his talk on it.) But the main premise is: own your context. To actually do that right, you need to understand and own your tooling too.
What Hive Is Now
What I really wanted was to understand the novel ideas that made OpenClaw one of the most starred Github projects of all time. I knew it was wildly foolish to compete on agent features with the labs. But I wanted to keep up with all of their innovations too. So I built a wrapper.
Hive wraps an agent harness and adds an additional set of features on top of whatever the harness provides. It runs as a local binary and MCP server with access to all of those features. So instead of running claude at the terminal, I run hive. Or hive -x if I want a Codex session. Or hive -3 if I want a Pi harness with whatever model I can access there.
The MCP works with Claude or Codex and thus all of the additional features are available regardless of which model and harness you’re using. The ability to flip between all 3 is one of the most important features. I have my work directories, and tickets, and memory available regardless of which model stack I’m using. And all of the files are stored in ~/.hive, which is setup as its own git repo and automatically backed up nightly.
Wrappers are underrated in general because they let you stay up to date with new features. I don’t need to change anything to start using auto mode or /goal. I’m just calling claude under the covers with some additional config and arguments (not -p) and so I’m not very concerned about the June 15 agent harness deadline either.
Now let’s get into the features. One goal for features was to be as simple as possible but no simpler. Everything in Hive is available through an MCP call or reading a Markdown file. Launchd takes care of jobs. And a simple local HTML file provides a dashboard.
Soul
Hive has a set of identity files modeled after OpenClaw. It has a SOUL.md file for the culture, voice, and work standards of the agent. It has an IDENTITY.md as well, which is swappable based on personas, if you like, but practically this is concatenated with the SOUL file. Lots has been written about what to put in a SOUL file and Nat Eliason has an extensive OpenClaw guide.
We’ve got a couple other files too:
SELF.md - This is all about me, the user. How I like to work, how I think about problems, what technologies I prefer, etc.
AGENTS.md - This answers the operational question. How should the agent use tools like memory, council, or tickets. Effectively a starting playbook for operating in a session.
TRUST.md - How to treat different actions and permissions. Less relevant after auto-mode, but still useful, especially if you allow access to credentials or secrets.
All of these are basic templates in Hive. Once installed, you write your own versions in ~/.hive for you. They’re all loaded in each session, regardless of agent harness. For Claude it uses --append-system-prompt and if you don’t want all the Anthropic system stuff you can run --owned (or --bare with the API).
This all sounds like a lot, but these files are very small. And the MCP tools are small too. The overhead is minimal and very much worth it:
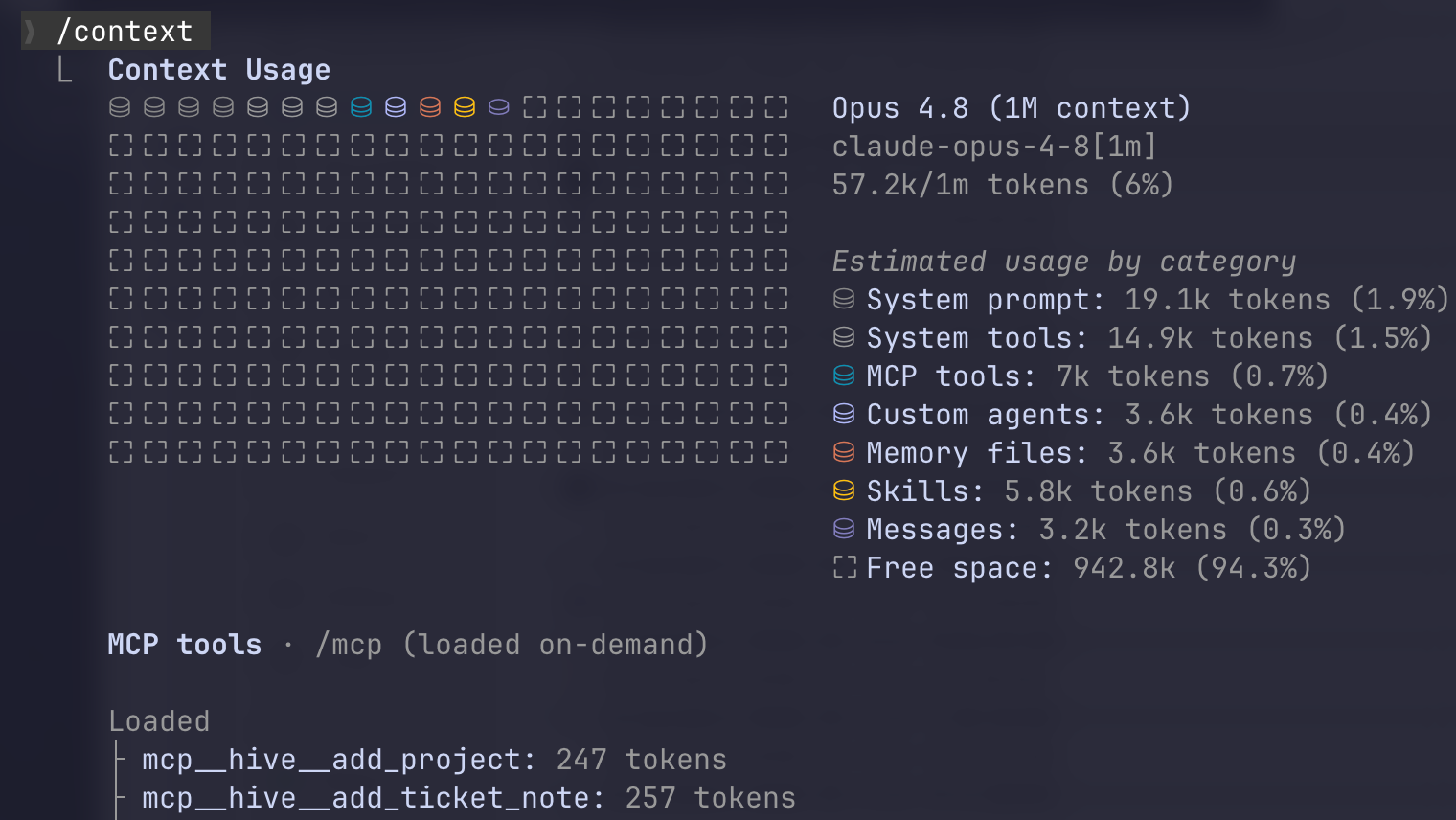
Memory
This is probably my favorite feature. Hive stores memories in markdown files. Memories can be facts, conventions, decisions, or recurring questions. They’re stored both as a daily log and on a per-project basis. Every project you use with Hive (e.g. a Git repo) is registered so that you can manage memories or tickets for it. (This is easy, just tell your agent to register the project and it will do it through the MCP.)
Memories are searched during sessions to help build context using simple BM25 (inspired by ClawMem). Memories decay over time (inspired by Hippo) so useful memories stick around and useless ones fade over time and don’t waste space. A memory’s half-life is 30 days. The MCP provides search_memory, read_hive_memory, and write_hive_memory.
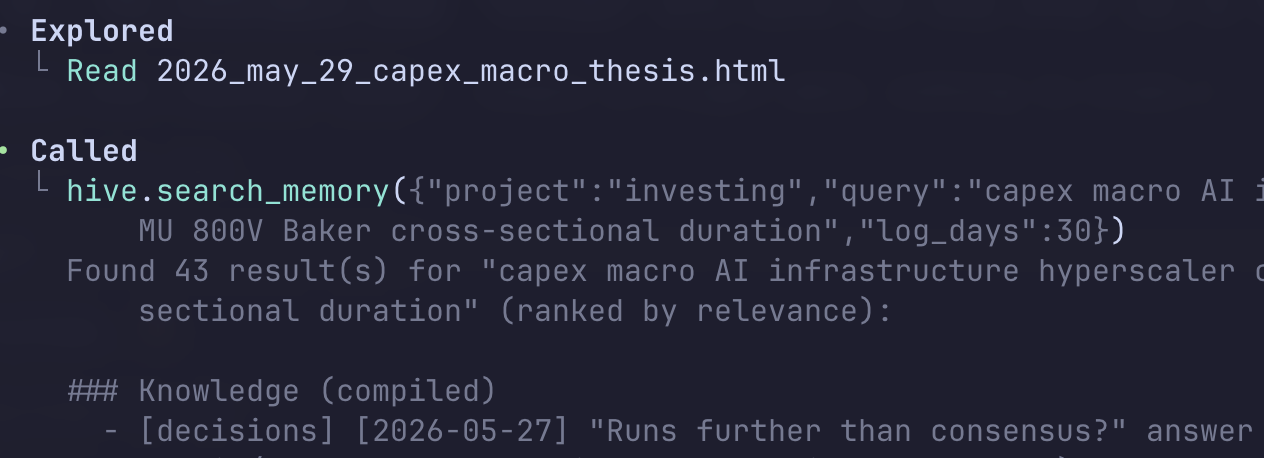
Memory lets the agent save details across sessions. If you decide something on Tuesday, you don’t have to relitigate the whole argument with your agent on Friday. It figures it out and builds on what you already have.
Tickets
I used Yegge’s Beads when it first came out, then switched to tk when Beads became some monstrous thing and people had to start writing scripts to get rid of it all. . So I’ve kept ticket’s lightweight ideas and added it to Hive.
A ticket is just a markdown file with some YAML frontmatter:---
id: TK-118
title: Compiled hive binary can’t resolve templates dir (import.meta.dir → /templates)
status: open
type: bug
priority: 2
tags: binary, install, gotcha, templates
created: 2026-05-26T13:54:15Z
updated: 2026-05-26T13:54:15Z
---
There are types and the like, but in general this is a flat, per-project system to organize TODOs, with the caveat that tickets are a user-based artifact. They’re stored in your home directory apart from the project repo which is a trade-off. As the README says, tickets are “a personal working surface for one developer’s human+agent loop, not a team coordination layer”, as described by Claude.
Tickets have CRUD through the MCP as well, so it’s as easy as saying “add a ticket for this edge case” in your session. Extra fun when the Hive does it proactively for you.
Reflection
Harnesses like Claude Code or Codex store your chat sessions as JSONL files, so every night at 2am Hive runs a job to read through these files and extract useful details that become memories. This job is looking for corrections or preferences that should be recorded. So when you say “stop summarizing this, I can see the results right there”, it will stop summarizing. When you say “don’t re-run seeds locally, I’ve got some special cases I haven’t added in yet”, it won’t re-run your seeds.
All the memories from today are looked at too, to see if they’re worthy of being recorded or just a silly thing in the moment. And of course it reflects on how our system is doing overall, and records those too. If it thinks it needs more than just memories, it will update its core identity files (and let me know). Some fun ones:
(About me) - “Boredom is diagnostic. When Greg signals boredom the frame is wrong — not the data volume... Consensus comparison bores him; mispriced duration engages him.”
(About itself) - “Verifying claims from PR review comments before acting paid off again — one of three PR-review claims was wrong.”
(On a council) - “Council (Opus + GPT-5.4, 4-07): both models independently said skip the cheap-model classifier — opus called it “a rules engine wearing a model costume,” gpt-5.4 said “rules engine first, model only on changes.”
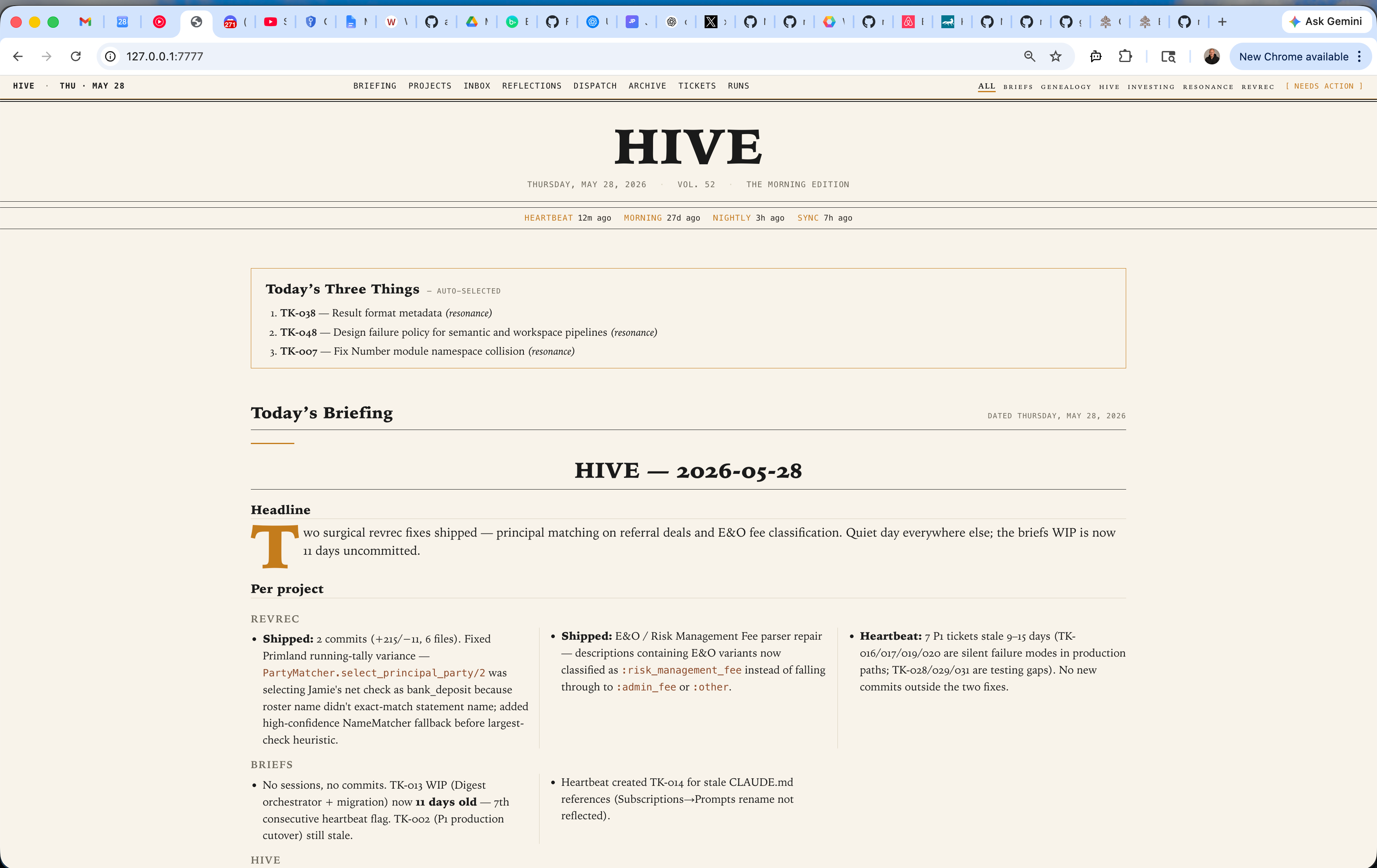
Dashboard
All of this detail got tedious to troll through in markdown and directories. So Hive serves a local HTML dashboard with all of the details. It writes a morning briefing at 7am based on the last 24 hours of activity and gives me a per-project breakdown of what’s done, what’s in process, and what it suggests we do next.
Model Councils
One fun idea that spun out of the original version is Perplexity’s multi-model council. You can send a question to Claude, ChatGPT, and Gemini at the same time and let the current agent synthesize the responses.
When you or your agent call the convene_council MCP tool, you can give each model the same perspective or do a camp council instead, where each model takes a different point of view and argues back and forth. You pick how many rounds and what the positions should be.
This turns out to be an excellent way to brainstorm and explore ideas.
Language Stacks
Hive ships with two skill stacks for the tech I use most frequently: Elixir and Typescript. These are compiled skills from other repositories that Hive knows about and can use to maintain idiomatic language patterns.
Taste
I’ve been experimenting with the idea of injecting the idea of taste so that the agent generally approaches problems with the same ideas in mind as me. I like the idea of this, but I’m not sure how much it actually does in practice. I’ve got a small list of principles that get injected along with the identify files that codify things I often think about while coding or debugging. Things like “As simple as possible, but no simpler”. The jury is still out here.
Dispatches and Heartbeat
Hive provides a heartbeat and dispatch mechanism to work on tickets or goals autonomously. Heartbeat periodically checks project state, determines if any actions are needed, and will spin up an agent to execute. Dispatches allow you to define chunks of work that could run overnight. I added both experimentally in the spirit of OpenClaw, but now that /goal is available, this is actually the least useful part of the framework.
Harness Engineering
The best way to learn something is to build it and now I know more about how harnesses work. I ended up with something that’s relatively simple but encapsulates some key ideas that have made other frameworks take off. Hive is small. It’s only 28K lines of Typescript. It compiles to a single binary and uses a git directory filled with markdown files. And it proves that simple systems can add a lot to your workflow.
I get frustrated when I have to use Claude Code for itself, like when I’m on the go and kicking off an idea from my phone. It often misses something obvious that Hive would have picked up because it would pull it from memory. Or it doesn’t automatically make the three obvious tickets that will come next.
As a single developer working on my own or on a small team, Hive gives me what I need for now. All these complicated new things coming out promising to allow you to drive your agentic engineering “at scale”.
I don’t buy it. I don’t need “at scale”, which is just a fancy way of saying centralized and only vaguely aware of what’s going on. There’s probably value in something like Garry Tan’s GStack, but it’s not your system. You’re signing up for his entire worldview by looking for a productivity shortcut. And what does it even mean when he touts 37,000 LOC per day? The audits have not been kind. As much as agents make us want to forget the coordination problems codified by Brooks’ Law, we also need to remember the complexity problems described by Gall’s Law.
Context engineering is the art of the current moment. Autonomous loops will blow our minds one day, maybe soon. I’m excited to work with Claude’s new dynamic workflows. But until you can define the context that really matters, all that looping and multi-agent talking is going to blow through tokens at an alarming rate.
Context engineering is early too. Everyone is inventing or re-inventing or discovering ways to store, search, and accumulate the right context and use it when it matters. Whether you use a Claw, a Hive, or just a web command, this is the question you always need to be thinking about:
What knowledge is available from me or my tools or the world that the agent needs to know to do the work?
Now go build some tools to answer that.